
The moment your AI agent can send an email, it can forward confidential data. The moment it can read files, it can exfiltrate them. The moment it can execute a workflow, it can be hijacked to execute a different one.
This is not a hypothetical. In 2025 and 2026, critical CVEs have been assigned to Microsoft Copilot (CVSS 9.3), GitHub Copilot (CVSS 9.6), and Cursor IDE (CVSS 9.8) — all exploiting the same fundamental weakness: AI agents operating with ambient trust and no external enforcement boundary. Google’s threat forecasting identifies targeted prompt injection against enterprise AI as one of the fastest-growing attack vectors of 2026.12
We are not running controlled experiments anymore. Agents are in production, touching sensitive data, taking real actions. And most organizations are securing them with the same tools they’d use for a web application. That’s the wrong model entirely.
Why can’t traditional security tools protect against AI agent threats?
Traditional security controls are syntactic. A firewall knows about IPs, ports, and packet signatures. An intrusion detection system knows about known-bad patterns. None of them have any idea what your recruiting agent intends to do when it initiates an HTTP connection to an external server — whether it’s querying an approved job board or forwarding candidate data to an attacker’s endpoint.
You cannot solve a semantic problem with syntactic tools.
The deeper issue is that agents have no inherent identity in most current deployments. The default pattern — the Identity Inheritance Model — is that agents inherit whatever credentials belong to the human or service account that deployed them. You know they have an API key. You don’t know which specific agent instance is using it, what it did with the data it accessed, whether its runtime behavior has been tampered with via prompt injection, or how to revoke access for a single agent without disrupting the entire fleet.3
Prompt injection — where an adversary embeds instructions in data the agent processes — has become the functional equivalent of remote code execution. When an agent has tool access, a malicious instruction hidden in a PDF, email, or document doesn’t just corrupt the model’s output. It executes with the agent’s full permissions, against real systems, with an audit trail that reports the action as legitimate automation.4
What does out-of-band proxy enforcement actually look like in practice?
Pedro Franceschi, CEO of Brex, articulates the correct framing: agent security is an engineering problem, not a philosophical impasse. His team built a response called “crab trap” — an HTTP proxy that intercepts all traffic from agent instances and routes it through a separate LLM that screens each action against a defined policy, then blocks at the network layer without the primary agent knowing the control exists.
The key phrase is without the primary agent knowing. The out-of-band positioning is what gives this architecture its teeth. An agent cannot reason its way around a control it has no visibility into. A prompt injection attack that successfully compromises the primary model cannot instruct that model to disable monitoring it cannot perceive. The agent’s compromise does not automatically produce a network-level breach.
The Franceschi framing holds: you don’t need to trust the agent. You need to trust the proxy and the topology. Those are things you can actually engineer and verify.
This insight is now being validated at industry scale. Cisco has built a Semantic Inspection Proxy along the same principles — sitting inline, analyzing intent rather than patterns, evaluating whether agent actions conform to defined policy. Microsoft’s Entra Agent ID and AI Gateway implement Prompt Shield at the network layer, enforcing guardrails across all AI apps without code changes. The CNCF has an active project defining an Agent Gateway standard as the policy enforcement point for all agent traffic.567
The pattern is converging: a mandatory proxy layer between agents and the systems they touch.
What are the three security layers that must all fail for a breach to succeed?
A well-designed agent security architecture isn’t one control. It’s three independent layers, each of which must fail independently for a breach to succeed.
Layer 1: Semantic policy enforcement at the proxy. Every action an agent attempts is evaluated against a defined policy by a second AI system before it reaches the network. The policy is behavioral — “should this recruiting agent be contacting this external address?” — not just syntactic. Critically, implement this as an allowlist, not a denylist. An allowlist policy defines the small set of approved actions; everything else is blocked by default. Denylist policies fail open — gaps in your policy language become exploitable. Allowlist policies fail closed. Industry practitioners deploying agents at scale are reaching the same conclusion: “Here are the 5 things this agent can do, and only these” outperforms trying to enumerate every bad action.89
Layer 2: Subnet isolation. Without network topology enforcement, the proxy is advisory. A misconfigured agent, a compromised agent, or an agent with a sufficiently creative prompt injection could potentially route around it. Placing agents in a dedicated subnet with firewall rules that force all egress through the proxy converts the architecture from optional to mandatory. No packet leaves the agent environment without proxy traversal. This also provides blast radius containment: a compromised agent is topologically trapped. It can enumerate other agents in the subnet but cannot reach corporate infrastructure or external systems without proxy authorization. Lateral movement is bounded by architecture, not just policy.
Layer 3: Per-Actor identity and differentiated traffic paths. This is the layer that moves the architectural design pattern from “something came from the agent subnet” to “Agent Instance 7 of Jim the Recruiter made exactly these 43 requests, 3 of which were blocked at 14:32 UTC.” Per-Actor identity — implemented via mTLS certificates, short-lived JWTs scoped to individual task instances, or SPIFFE-based workload attestation — unlocks four capabilities simultaneously: role-specific policy at the proxy (Jim’s allowed-action profile differs from a financial workflow agent), granular revocation without fleet disruption, forensic audit trails attributable to specific instances, and detection of agent impersonation attacks. The MCP specification formally adopted OAuth 2.1 as its authorization framework in March 2025 specifically to solve this problem.1011
Separating agent traffic paths from human traffic paths is not administrative convenience — it’s a security property. Human Actors and AIgentic Actors have fundamentally different behavioral profiles, risk profiles, and appropriate action sets. Rate limiting appropriate for a human (who cannot make 10,000 API calls per second) is not appropriate for an agent fleet. Anomaly detection calibrated for human patterns will miss agent abuse, and vice versa. Mixing the two paths degrades monitoring quality for both.
What does the combined architectural design pattern look like in practice?
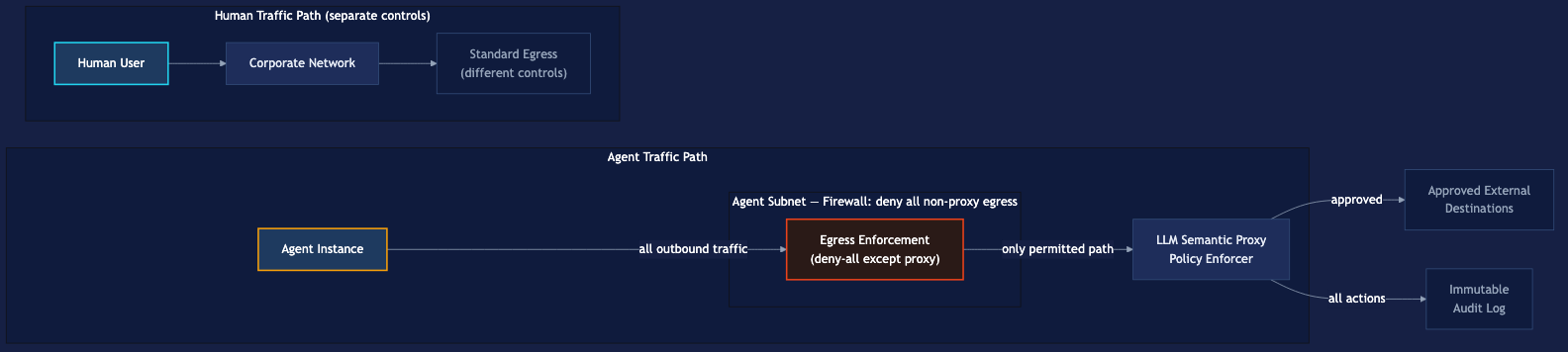
The properties this architectural design pattern delivers:
- Topology-first safety. No agent is trusted by virtue of network position — topology removes ambient trust structurally. Whether an agent’s credential is valid or compromised, the network determines what it can reach.
- Semantic + syntactic + topological defense in depth. Three independent layers, each with different failure modes.
- Identity-attributed audit trail. Not “the agent fleet made requests.” Specific agent instances, specific actions, specific blocks.
- Prompt injection resilience at the architectural level. Model-level compromise does not automatically produce network-level breach.
- Hard blast radius limits. Topology enforces containment independent of whether your policy is perfectly written.
Research on 300,000 adversarial prompts shows the compounding effect in practice: basic system prompt defenses alone allowed 7% of attacks through. Adding content inspection dropped that to 0.2%. Adding prompt injection detection dropped it further to 0.003% — a 2,300-fold improvement from layered defense.4
What are the honest limits of this architecture?
This architectural design pattern has two real limitations worth naming.
The monitor LLM can itself be targeted. An adversary who understands your policy could craft requests designed to pass the monitor’s screening while still achieving harmful outcomes. The architectural response is twofold: keep the monitor’s policy opaque to the primary agent (the out-of-band positioning already accomplishes this), and log everything comprehensively so that patterns visible only in aggregate can be detected retrospectively.
Policy completeness is the harder problem. The proxy can only block what the policy covers. This is precisely why the allowlist principle matters — a narrow allowlist (“permit only these actions”) fails closed when it encounters novel behavior. A broad denylist (“block these specific bad things”) fails open.
Why is the window to build this architecture narrowing?
The OWASP Top 10 for Agentic Applications, released December 2025 by more than 100 security researchers, identifies Agent Goal Hijack and Identity & Privilege Abuse as the top threats facing production AIgentic systems. The EU AI Act’s August 2026 deadline for high-risk AI compliance specifically requires demonstrating robustness against prompt injection. Regulatory pressure and production reality are converging on the same point.112
The Franceschi insight is correct: this is an engineering problem. The proxy architectural design pattern — semantic enforcement, subnet isolation, per-Actor identity — converts the unpredictability of agent behavior into a containment and verification problem. You don’t have to solve the hard AI alignment question. You have to build a boundary you can trust around an agent you can’t fully predict.
That boundary is available to build today.
Revised 2026-04-27. Per-Actor identity replaces per-agent identity in governance contexts; Human Actors and AIgentic Actors capitalized as formal ontology classes; topology-first safety replaces zero trust for agents in the five-property list, reflecting the distinction between topology-first safety and Zero Trust attribution — see Governing AIgentic Actors for the authoritative framing; architectural design pattern replaces architecture as standalone noun. Substantive content unchanged.
Footnotes
-
Prompt Injection: Types, Real-World CVEs, and Enterprise Defenses — Critical CVEs assigned in 2025–2026 including EchoLeak, GitHub Copilot RCE, and Cursor IDE vulnerabilities exploiting AI agents with ambient trust. ↩ ↩2
-
AI Agent Security 2026: Google’s Forecast and How to Fix the Gaps — Google expects a significant rise in targeted prompt injection attacks against enterprise AI systems throughout 2026. ↩
-
Why AI Agents Need Zero Trust Identity (and How to Build It) — OAuth was designed for humans delegating access to apps. mTLS verifies connections, not agent identity. ↩
-
How to Deal with the 2026 Agent Wave — Prompt injection is now an RCE-equivalent. When agents have tool access, injecting instructions into processed data executes with the agent’s full permissions. ↩ ↩2
-
Redefining Zero Trust in the Age of AI Agents and Agentic Workflows — Cisco’s Semantic Inspection Proxy redefines zero trust with intent-based security for AI-powered threats. ↩
-
MCP and Zero Trust: Securing AI Agents with Identity and Policy — How to secure AI agents with identity, policy, and fine-grained authorization using MCP and Zero Trust. ↩
-
Zero-Trust Agent Architecture: How to Actually Secure Your Agents — Microsoft’s Entra Agent ID and AI Gateway implement Prompt Shield at the network layer. ↩
-
Denylist vs Allowlist for AI Agent Guardrails — Every unexpected behavior becomes another new policy you need to block. The opposite approach — allowlisting — outperforms at scale. ↩
-
Allowlists vs. Denylists in Multi-Tenant Access Control — Allowlists implement default-deny behavior, while denylists implement default-allow behavior. ↩
-
Zero Trust for AI Agents: Ephemeral Credentialing Blueprint — Reducing the AI agent credential exposure window by over 99% with ephemeral credentialing. ↩
-
What Developers Building with AI Agents Need to Know — The OWASP GenAI Security Project released the Top 10 for Agentic Applications in December 2025. ↩
-
OWASP Top 10 for Agentic Applications — ASI01 Agent Goal Hijack, ASI02 Tool Misuse, ASI03 Identity & Privilege Abuse identified as top threats. ↩
