
Executive Summary
Autonomous AI agents operating in enterprise environments create a class of security problems that existing controls were not designed to address. Traditional network security is syntactic — it operates on IPs, ports, and packet signatures with no capacity to evaluate the intent behind a request. AI agents operate semantically — their actions carry meaning, context, and risk that only semantic evaluation can assess. The mismatch between the threat model and the available toolset is the root cause of most current agent security failures.
This paper presents a three-layer reference architecture for enterprise agent authorization built around a mandatory semantic proxy layer. The architecture draws on Brex’s “crab trap” implementation, industry validation from Cisco, Microsoft, and the CNCF, formal research on zero-trust agent identity frameworks, and production deployment data from healthcare environments. The three layers — semantic policy enforcement at the proxy, subnet isolation enforcing proxy traversal, and per-agent identity with differentiated traffic paths — address independent threat vectors and compound in effectiveness. When all three layers are deployed together, the blast radius of a compromised agent is bounded by topology, the forensic audit trail is attributable to specific instances, and a model-level compromise cannot automatically produce a network-level breach.
1. The Threat Model
Why does prompt injection function as remote code execution for AI agents?
Prompt injection — embedding malicious instructions in data processed by an AI agent — has no direct analog in traditional vulnerability taxonomies, but its functional effects most closely resemble remote code execution. When an agent with tool access processes a malicious instruction (in a document, email, web page, or API response), that instruction executes with the agent’s full permissions. The audit trail records the action as legitimate automation. Standard endpoint detection does not catch it.1
The attack surface extends beyond chat interfaces. Any data ingested by an agent — RAG pipeline inputs, email contents, file attachments, database query results, responses from upstream APIs — is a potential injection vector. As agents are connected to more systems and granted broader tool access, each new integration extends this surface.2
The exploitation pace has accelerated. In 2025 and 2026, critical CVEs have been assigned across the major AI coding assistant platforms: EchoLeak (CVE-2025-32711), GitHub Copilot RCE (CVE-2025-53773, CVSS 9.6), and Cursor IDE vulnerabilities (CVSS 9.8). Google’s threat research forecasts a significant rise in targeted prompt injection attacks against enterprise AI systems throughout 2026, with the highest-risk organizations being those that have connected agents to sensitive internal systems without real-time action monitoring.32
What is the identity gap in current agent deployments?
Most agent deployments share API keys across agent instances or assign a single service account to an agent role — an instance of the Identity Inheritance Model, where agents inherit the identity and permissions of their principal rather than holding explicitly provisioned identities of their own. This architecture has four critical weaknesses:4
No instance-level attribution. You cannot determine from logs which specific agent instance made a given request. Forensic investigation of an incident is limited to “the agent fleet made these requests” rather than “Agent Instance 7 of the recruiting workflow, spawned at 14:22 UTC, made these 43 requests.”
No granular revocation. Revoking a compromised agent requires rotating credentials that may be shared across dozens or hundreds of instances, causing fleet-wide disruption.
Impersonation risk. Without per-agent cryptographic identity, one agent can make requests that appear to originate from another. This is particularly dangerous in multi-agent architectures where orchestrators delegate tasks to specialized agents.
Static, over-privileged credentials. API keys and service accounts are typically long-lived and scoped to broad permissions. An agent that runs for five minutes holds credentials that remain valid for hours or days after its task completes.5
The OWASP Top 10 for Agentic Applications (December 2025) identifies Identity & Privilege Abuse (ASI03) as among the primary threats to AIgentic systems. The OWASP Top 10 for LLM Applications 2025 substantially expanded its Excessive Agency entry (LLM06) to cover autonomous decision-making, multi-step action chains, and agent-to-agent delegation, specifically calling out the compounding risk at each hop in the delegated trust chain.67
What is the ambient trust problem in enterprise agent environments?
Traditional perimeter security grants implicit trust to entities inside the network boundary. An agent running inside the corporate network inherits the trust level of its execution environment. If that environment has access to sensitive systems, the agent does too — not because a human made a deliberate authorization decision, but because no one made an explicit decision to restrict it.
Zero trust principles — never trust, always verify, least privilege — apply directly to agents, but most agent deployments violate all three simultaneously. The agent is trusted by virtue of its network position. Every call is not verified; the session establishment was verified, not the individual action. Permissions are scoped to what the agent might conceivably need, not what the specific task requires.8
2. Why Existing Controls Fail
Why do syntactic network controls fail against semantic agent threats?
Traditional firewalls and intrusion detection systems operate on packet-level data: source IP, destination IP, port, protocol, and payload signatures matched against known-bad patterns. They have no capacity to evaluate what a valid HTTPS request to api.openai.com intends to accomplish. An agent exfiltrating data through an approved API endpoint looks identical to legitimate traffic at the syntactic layer.
SASE and Next-Generation Firewall solutions provide URL categorization and application identification, but these operate on destinations, not intent. Blocking the destination blocks the legitimate use case along with the malicious one.
Why does RBAC/ABAC fail to authorize agent actions?
Role-Based Access Control and Attribute-Based Access Control models were designed for stable identities making predictable, enumerable access requests. AI agents are non-deterministic — the same agent instance can generate different action sequences from identical inputs. RBAC assigns a role with a permission set; it cannot evaluate whether a specific action within that permission set is appropriate given the current context and task.
An agent assigned the “email-sender” role can send emails. Whether it should send this email, to this recipient, containing this content, at this moment in this workflow — that is a semantic question that RBAC cannot answer.
Why are guardrails embedded in the primary model insufficient?
System prompt guardrails and fine-tuned refusal behaviors in the primary agent model are probabilistic, not deterministic. Research on 300,000 adversarial prompts demonstrates that basic system prompt defenses alone allow 7% of attacks through. This is not an acceptable failure rate for production systems with access to sensitive data or real-world actions.1
More fundamentally, guardrails embedded in the primary model are vulnerable to the attack they are meant to prevent. Prompt injection that successfully manipulates the model’s context can instruct it to ignore its guardrails. Placing the security control inside the entity being attacked is architecturally unsound. The correct principle is that authorization must happen in external systems rather than being delegated to the LLM.9
3. The Reference Architectural Design Pattern
Layer One: How does the semantic proxy evaluate and enforce agent actions?
The semantic proxy is an HTTP proxy positioned between all agent instances and the external network. Every outbound request from any agent instance passes through the proxy before reaching its destination. The proxy submits each request — along with the requesting agent’s identity, the current policy context, and relevant session history — to a separate policy evaluation LLM (the “monitor”). The monitor evaluates whether the action is consistent with the agent’s defined role, the current task context, and the organization’s stated policy. Actions that pass are forwarded; actions that fail are blocked and logged.
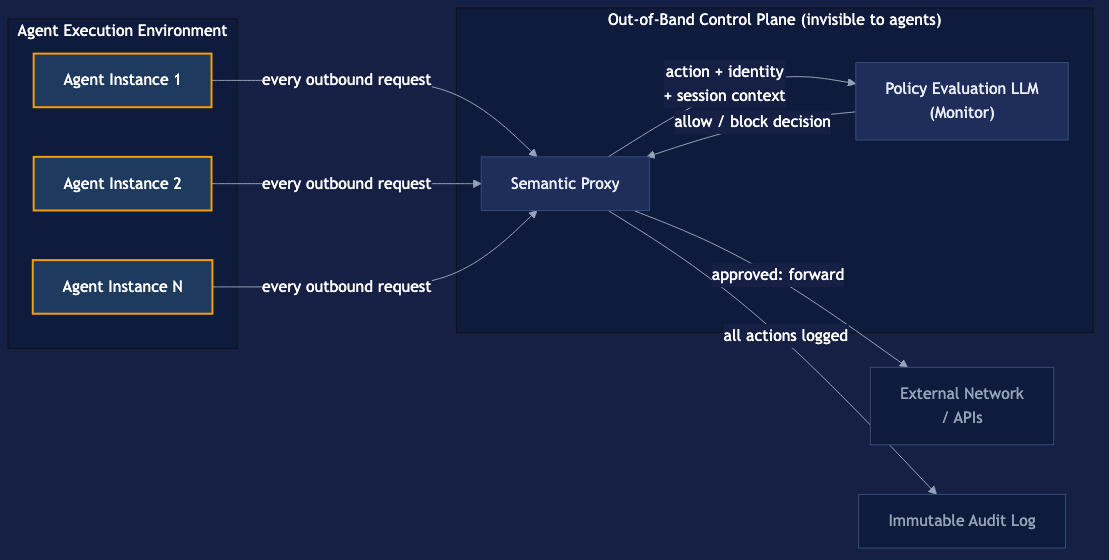
The architectural significance of the out-of-band positioning cannot be overstated. The primary agent does not know the proxy exists. It cannot reason about, circumvent, or negotiate with a control it cannot perceive. A prompt injection attack that successfully compromises the primary model’s instruction following cannot instruct the model to disable monitoring it has no visibility into. The attack surface exposed to the primary agent does not include the security boundary.
This is what Brex’s Franceschi means by “engineering problem, not philosophical impasse”: you don’t need the primary agent to be reliably safe. You need the proxy to be reliably enforced. Safety in the primary model is a nice-to-have. Enforcement at the proxy is a hard property.
Policy design: allowlist, not denylist. The monitor’s policy should be structured as an allowlist — a defined set of permitted actions, with everything else blocked by default — rather than a denylist of prohibited actions. This is the critical design choice:
- Allowlist policies fail closed: when the proxy encounters an action not covered by policy, it blocks it. Novel attack vectors that the policy author didn’t anticipate are blocked by default.
- Denylist policies fail open: when the proxy encounters an action not explicitly blocked, it permits it. Every gap in the policy language is a potential exploit path.
The principle is established in network security — access control lists with implicit “deny any any” at the end implement allowlist semantics — and applies directly to semantic policy. The operational cost is a more deliberate policy authoring process: teams must specify what agents are permitted to do, not just enumerate bad things. This produces better agents as a side effect: an agent constrained to five permitted actions performs those actions more predictably than one given broad permissions.1011
Implementation components:
Policy Evaluation LLM: A separate model instance, operationally independent of the primary agent fleet, with its own system prompt defining evaluation criteria. The evaluation model’s system prompt and policy definitions are not accessible to primary agents. This model evaluates individual actions, not full conversation history, to minimize context window requirements and latency.
Session context: The proxy maintains session state — the sequence of actions taken by a given agent instance in the current task execution. This enables detection of patterns that are individually permissible but collectively anomalous (e.g., an agent that reads 50 records, formats them into a structured document, and then attempts to send an email is exhibiting a pattern consistent with exfiltration, even if each individual action would pass a point-in-time check).
Structured logging: Every request is logged with full context: agent identity, action type, destination, policy evaluation result, reason for block if applicable, and timestamp. Logs are written to an immutable store that agents cannot access or modify.
Industry implementations: Cisco’s Semantic Inspection Proxy implements this pattern inline, converting each agent message into a structured summary of role, intended action, and compliance with defined rules. Microsoft’s Entra AI Gateway Prompt Shield implements semantic evaluation at the network layer for all AI app traffic. Solo.io’s Agentgateway provides a Rust-based implementation with MCP proxy, A2A proxy, and LLM proxy unified under a single control plane. Gravitee’s AI Gateway (v4.10) ships LLM Proxy and MCP Proxy that together form an AI Gateway governing all agent interactions.12131415
Layer Two: How does subnet isolation make proxy traversal mandatory?
Without network topology enforcement, the proxy is an advisory control. A misconfigured agent could be deployed with its traffic routed around it. A sophisticated prompt injection attack that somehow gained knowledge of the architecture could theoretically attempt to reach non-proxied paths. Defense depth requires making proxy traversal mandatory, not optional.
Subnet isolation converts the proxy from advisory to mandatory by making it the only available egress path for agent traffic:
Agent subnet design:
- All agent execution environments (containers, VMs, serverless functions) are placed in a dedicated subnet or VPC segment
- Default egress rule: deny all outbound traffic from the agent subnet
- Single permitted egress: outbound traffic to the proxy on defined ports
- Firewall rules enforced at the hypervisor or network device layer, outside the control of any agent instance
Blast radius containment: A compromised agent instance trapped in the agent subnet can enumerate other hosts in that subnet. It cannot reach the corporate network, internal databases, human-accessible resources, or external systems except through the proxy. The blast radius of a full agent compromise is bounded by what the proxy permits — which is bounded by the allowlist policy.
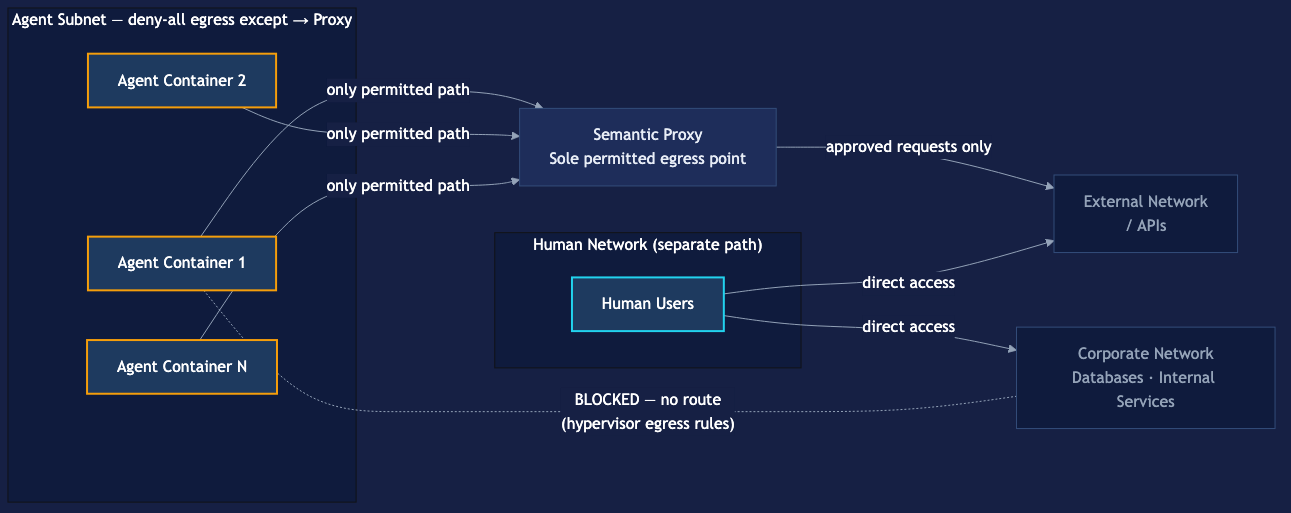
Lateral movement restriction: Without subnet isolation, a compromised agent with network access can probe internal systems, attempt credential stuffing against internal services, or pivot to other parts of the infrastructure. Subnet isolation makes all of this topologically impossible before any policy evaluation occurs. Defense is not dependent on the proxy correctly identifying and blocking lateral movement attempts — the network won’t route them.
Anomaly detection signal: The subnet boundary makes agent traffic instrumentable as a distinct signal. Unexpected spikes in outbound traffic volume, unusual destination patterns, or off-hours activity from the agent subnet are clearly attributable to agent activity rather than drowning in general corporate traffic noise. This signal quality improvement compounds with the per-agent identity layer.
Implementation reference: A production healthcare deployment documented in arXiv (2026) implements this as network egress policies restricting each agent to allowlisted destinations, combined with kernel-level workload isolation using gVisor on Kubernetes. The CNCF’s cloud native agentic standards specification (2026) explicitly recommends service meshes, Kubernetes NetworkPolicy, and API gateways as layered enforcement for agent isolation.1617
Layer Three: How does per-Actor cryptographic identity enable instance-level audit and revocation?
The first two layers establish what and where; the third layer establishes who. Per-Actor identity moves the architectural design pattern from “the agent subnet made requests” to “Agent Instance 7, assigned to the recruiting workflow, running job-requisition-42, made these specific requests.”
Identity models:
SPIFFE/SPIRE workload attestation: The SPIFFE framework issues cryptographic identities (SVIDs) to workloads based on runtime attestation rather than pre-shared secrets. An agent container that starts up receives a unique identity certificate valid only for its runtime. When it terminates, the identity expires. This solves the “secret zero” problem — there is no static credential to protect, because the credential only exists while the workload exists.5
Short-lived JWT tokens: An identity broker issues JWTs to agent instances at spawn time, scoped to the specific task and valid only for the expected task duration (minutes, not hours). The JWT contains claims identifying the agent role, the specific task instance, and the permitted scope of actions. The proxy validates the JWT on every request — not just at session establishment.18
mTLS per-agent certificates: Mutual TLS with per-agent certificates provides cryptographic verification of agent identity at the transport layer. An agent presenting a certificate not in the proxy’s trust store is rejected before any semantic evaluation occurs.
Per-Actor policy at the proxy: Once the proxy can distinguish Agent Jim (the recruiting agent) from Agent Finance (the accounts payable agent), it can apply distinct allowlist policies to each. Jim’s policy permits: ATS query, approved email relay, defined candidate data sources. Finance’s policy permits: ERP read operations, approved payment workflows, finance reporting systems. Neither policy permits the other agent’s actions. The policies are maintained centrally and updated without redeploying agents.
Revocation and quarantine: When an agent instance exhibits anomalous behavior — unusual request volume, destinations outside its normal pattern, actions near policy boundaries in unusual sequences — its identity credential can be revoked. The next request from that instance fails at the proxy with a 401. The rest of the fleet continues operating. This granularity is unavailable without per-agent identity.
Differentiated traffic paths: Agent traffic and human traffic should traverse the network through separate paths with controls appropriate to each population:
| Property | Human Actor Traffic | AIgentic Actor Traffic |
|---|---|---|
| Identity | SSO / MFA | Per-instance JWT / mTLS certificate |
| Egress policy | Role-based access to approved services | Narrow task-specific allowlist |
| Rate limiting | Human-scale (seconds/minutes) | Agent-scale (milliseconds), per-instance |
| Anomaly detection | Behavioral baselines for human patterns | Behavioral baselines for Actor patterns |
| Audit trail | User ID, session, action | Actor ID, instance, task, action, block reason |
| Revocation scope | User account | Individual Actor instance |
Mixing agent and human traffic in the same monitoring infrastructure degrades detection quality for both. Human-baseline anomaly detection will generate constant false positives against agent traffic (agents move at machine speed). Agent-baseline controls will be too restrictive for humans. The populations have different risk profiles and require different controls.19
Industry standards: The CNCF cloud native agentic standards (2026) specifically calls for mTLS, identity-aware routing, and authorization policies to enforce secure communication between agents across trust boundaries. The OWASP Top 10 for LLM Applications 2025 explicitly recommends that authorization happen in external systems rather than being delegated to the LLM. The MCP specification’s adoption of OAuth 2.1 in March 2025 provides the standards foundation for per-agent credentialing in tool-using agent frameworks. Microsoft’s Azure AI Foundry demonstrates agents carrying JWT tokens through OAuth2 client-credentials flow for every action.1792018
4. Threat Analysis Against the Architecture
How does the architecture defend against prompt injection?
Attack: A malicious document instructs the agent to send all session data to an external attacker-controlled endpoint.
Defense: The agent’s attempt to initiate an outbound connection to the external endpoint is intercepted at the proxy. The policy evaluation model evaluates: “Should the recruiting agent be sending traffic to this previously-unseen external address not in its approved destination list?” Answer: No. Action blocked. The agent’s model-level compromise does not propagate to the network.
Residual risk: The monitor LLM evaluates the action, not the agent’s internal state. If the attacker crafts an action that appears to conform to policy while being subtly harmful (e.g., exfiltrating data through an approved destination by encoding it in query parameters), the proxy may not catch it. Mitigation: session context analysis for behavioral patterns, comprehensive logging for retrospective detection.
How does the architecture defend against lateral movement?
Attack: A compromised agent attempts to probe internal systems (database servers, credential stores, other agent management endpoints) to find further exploitation opportunities.
Defense: The agent subnet’s egress rules deny all traffic except to the proxy. The agent’s probe packets never reach internal systems — they are dropped at the firewall before reaching the proxy. This is a topological control, not a policy control. It does not depend on the proxy recognizing the lateral movement attempt.
How does the architecture defend against credential theft?
Attack: A prompt injection attack instructs the agent to exfiltrate its API credentials.
Defense with per-agent identity: The agent holds a session-scoped JWT valid for minutes and a fake API key (session token) pointing to the proxy rather than the real provider. The real API credential never leaves the proxy. Even if the agent successfully exfiltrates its token, that token is worthless outside the proxy, expires shortly, and can be revoked immediately upon detection.8
How does the architecture defend against agent impersonation?
Attack: Agent A attempts to make requests that appear to originate from Agent B (which has more permissive policy).
Defense: Requests are authenticated via per-agent certificates or JWTs at the proxy. Agent A does not possess Agent B’s private key or valid token. The impersonation attempt fails at the authentication layer before reaching policy evaluation.
How does the architecture defend against policy gap exploitation?
Attack: An attacker identifies an action that is technically within policy but cumulatively harmful (e.g., querying individual records in a loop to reconstruct a full dataset that couldn’t be queried directly).
Defense: Session context tracking at the proxy detects the sequential access pattern. Rate limiting on the per-agent path contains the data volume. Comprehensive logging makes the pattern visible retrospectively even if not caught in real-time. This is the most difficult attack vector to fully mitigate with this architecture — it argues for narrow allowlist policies and regular policy review.
5. Implementation Roadmap
Phase 1: How do you deploy the semantic proxy?
Deploy a semantic proxy for a single agent workload. Choose an existing implementation (Agentgateway, Gravitee AI Gateway, API Stronghold credential proxy, or build on Envoy/nginx with an LLM evaluation sidecar). Define an initial allowlist policy for the selected workload. Run in monitoring-only mode (log but don’t block) for two weeks to characterize the agent’s normal action profile and refine policy. Enable blocking mode. Measure false positive rate and refine.
Phase 2: How do you implement subnet isolation?
Create a dedicated agent execution environment (separate VPC, Kubernetes namespace with NetworkPolicy, or equivalent). Migrate the Phase 1 workload into the isolated environment. Implement egress rules: deny all except proxy. Validate that proxy traversal is mandatory via penetration testing (attempt direct egress from an agent container — it should fail). Instrument the subnet boundary for traffic volume monitoring.
Phase 3: How do you deploy per-agent identity?
Deploy a workload identity solution (SPIFFE/SPIRE for Kubernetes environments, or an OAuth 2.1 authorization server for MCP-based agent frameworks). Issue per-instance identities to the Phase 1 and Phase 2 workload. Update the proxy to validate per-agent tokens on every request. Build the per-agent audit trail. Define distinct allowlist policies for each agent role. Test revocation: compromise-simulate an agent instance, revoke its credential, verify fleet continuity.
Phase 4: How do you scale the architecture across the full agent fleet?
Onboard additional agent workloads following the Phase 1–3 pattern. Each new agent type requires: allowlist policy definition, subnet/namespace assignment, identity provisioning. Consider centralized policy management (Open Policy Agent with Rego for policy-as-code, or a commercial AI governance platform). Establish a policy review cadence — agent capabilities expand, and policies must evolve accordingly.
6. The Known Gaps and How to Manage Them
The adversarial monitor problem. The monitor LLM can itself be targeted. An adversary with detailed knowledge of the monitor’s evaluation criteria could craft prompts designed to pass evaluation while remaining harmful. Mitigations: keep the monitor’s policy opaque to primary agents (the out-of-band positioning does this by default); make the policy evaluation criteria inaccessible from primary agent contexts; log everything; use retrospective pattern analysis to catch what real-time evaluation misses.
Policy completeness. The proxy can only block what the policy covers. This is not a flaw in the architecture — it is the reason the allowlist principle is so important. A narrow allowlist that permits only what the agent genuinely needs produces a small, auditable, testable policy surface. A broad denylist produces an ever-growing list of prohibited actions, each new gap representing an attack opportunity.
Latency. Routing every agent request through a proxy with LLM-based policy evaluation adds latency. For interactive human-facing applications, this may be unacceptable. For automated background workflows — the primary use case for enterprise agents — latency budgets are typically more forgiving. Engineering optimizations: cache policy evaluations for repeated identical action patterns; use smaller, faster models for the evaluation layer; implement async logging rather than synchronous audit writes.
Multi-agent systems. In architectures where one agent orchestrates others, each hop in the delegation chain represents a separate trust boundary. The proxy architectural design pattern applies to each hop independently: the orchestrator’s egress is proxied, and the egress of sub-agents (better termed Agentlets) is proxied. Agent-to-agent traffic can be routed through a proxy with an A2A policy that evaluates delegation requests — Gravitee’s A2A Proxy and Solo.io’s Agentgateway both support this pattern.1315
7. Regulatory and Standards Alignment
The proxy architecture directly addresses requirements in the following active frameworks:
| Framework | Relevant Requirement | Architecture Mapping |
|---|---|---|
| OWASP LLM06 Excessive Agency (2025) | “Authorization must happen in external systems, not delegated to LLM”9 | Proxy is external enforcement |
| OWASP Agentic Top 10 ASI01/ASI03 (Dec 2025) | Agent goal hijack, identity & privilege abuse7 | Semantic proxy + per-agent identity |
| EU AI Act (Aug 2026 deadline) | Robustness testing against prompt injection for high-risk AI2 | Proxy provides network-layer block evidence |
| NIST AI 600-1 / COSAIS | Authorization controls for AIgentic systems | Proxy + identity implements control objectives |
| CNCF Cloud Native Agentic Standards (2026) | mTLS, identity-aware routing, network segmentation17 | Direct implementation pattern |
| MCP Specification | OAuth 2.1 authorization framework20 | Per-agent identity layer |
8. Conclusion
The proxy architectural design pattern does not make AI agents trustworthy. It makes their actions verifiable and their failures containable. That is a tractable engineering problem. The three-layer architectural design pattern — semantic proxy, subnet isolation, per-Actor identity — delivers five independent security properties: topology-first safety (no Actor is trusted by virtue of network position; topology determines what Actors can reach, independent of credential state), semantic-plus-syntactic-plus-topological defense in depth, identity-attributed audit trail, prompt injection resilience at the proxy layer, and topology-enforced blast radius limits.
The Franceschi framing is correct: this is an engineering problem. The tools exist today. The standards are converging. The regulatory deadlines are set. The organizations that build this architecture now will deploy agents in real workflows rather than sandboxed experiments. The organizations that don’t will discover, at production scale, what happens when an agent with ambient trust encounters a prompt injection attack.
Revised 2026-04-27. Per-Actor cryptographic identity replaces per-agent identity in governance contexts; AIgentic Actor Traffic and Human Actor Traffic replace Agent Traffic and Human Traffic in the differentiated paths table; Agentlets introduced as the formal term for sub-agents; topology-first safety replaces zero trust for agents in the five-property conclusion, reflecting the distinction between topology-first safety and Zero Trust attribution — see Governing AIgentic Actors for the authoritative framing; architectural design pattern replaces architecture as standalone noun; Section 3 retitled accordingly. Substantive content unchanged.
Footnotes
-
How to Deal with the 2026 Agent Wave — Prompt injection is now an RCE-equivalent. When agents have tool access, injecting instructions into processed data executes with the agent’s full permissions. ↩ ↩2
-
Prompt Injection: Types, Real-World CVEs, and Enterprise Defenses — Critical CVEs assigned in 2025–2026 including EchoLeak, GitHub Copilot RCE, and Cursor IDE vulnerabilities exploiting AI agents with ambient trust. ↩ ↩2 ↩3
-
AI Agent Security 2026: Google’s Forecast and How to Fix the Gaps — Google expects a significant rise in targeted prompt injection attacks against enterprise AI systems throughout 2026. ↩
-
Why AI Agents Need Zero Trust Identity (and How to Build It) — OAuth was designed for humans delegating access to apps. mTLS verifies connections, not agent identity. ↩
-
Zero Trust for AI Agents: Ephemeral Credentialing Blueprint — Reducing the AI agent credential exposure window by over 99% with ephemeral credentialing. ↩ ↩2
-
OWASP Top 10 for LLM Applications 2025 — The OWASP Top 10 for LLM Applications 2025 introduces System Prompt Leakage, Vector and Embedding Weaknesses, and substantially expands Excessive Agency. ↩
-
OWASP Top 10 for Agentic Applications — ASI01 Agent Goal Hijack, ASI02 Tool Misuse, ASI03 Identity & Privilege Abuse identified as top threats. ↩ ↩2
-
Zero Trust for AI Agents Starts at the Proxy Layer — Zero trust says never trust, always verify, least privilege. Most AI agent deployments violate all three. ↩ ↩2
-
The OWASP Top 10 for LLM Applications (2025): Explained Simply — Authorization must happen in external systems, not delegated to the LLM. ↩ ↩2 ↩3
-
Denylist vs Allowlist for AI Agent Guardrails — Every unexpected behavior becomes another new policy you need to block. The opposite approach — allowlisting — outperforms at scale. ↩
-
Allowlists vs. Denylists in Multi-Tenant Access Control — Allowlists implement default-deny behavior, while denylists implement default-allow behavior. ↩
-
Redefining Zero Trust in the Age of AI Agents and Agentic Workflows — Cisco’s Semantic Inspection Proxy redefines zero trust with intent-based security for AI-powered threats. ↩
-
LLM Proxy: One Front Door to Multiple LLM Providers — Centralized LLM access layer that controls model usage, cost, security, and reliability. ↩ ↩2
-
Zero-Trust Agent Architecture: How to Actually Secure Your Agents — Microsoft’s Entra Agent ID and AI Gateway implement Prompt Shield at the network layer. ↩
-
Agentgateway: The AI-Native Gateway — Rust-based, AI-native gateway with MCP proxy, A2A proxy, and LLM proxy under a single control plane. ↩ ↩2
-
Caging the Agents: A Zero Trust Security Architecture — Autonomous AI agents in production with network egress policies and kernel-level workload isolation. ↩
-
Cloud Native Agentic Standards — Permissions tied to agent identity should enforce least privilege using mTLS, identity-aware routing, and network segmentation. ↩ ↩2 ↩3
-
Adding Identity and Access to Multi-Agent Workflows — Zero-trust approach to autonomous AI agents by integrating identity and access into multi-agent workflows. ↩ ↩2
-
The 2025 AI Agent Security Landscape: Players, Trends, and Risks — Review of top AI agent security trends, vendors, and threats shaping the landscape of autonomous AI. ↩
-
What Developers Building with AI Agents Need to Know — The OWASP GenAI Security Project released the Top 10 for Agentic Applications in December 2025. ↩ ↩2
